Showing
- content/blog/2024/06/2024-06-18_campdays/index.md 172 additions, 0 deletionscontent/blog/2024/06/2024-06-18_campdays/index.md
- content/blog/2024/06/2024-06-18_campdays/lummerland_bruecke.jpg 0 additions, 0 deletions...t/blog/2024/06/2024-06-18_campdays/lummerland_bruecke.jpg
- content/blog/2024/06/2024-06-18_campdays/lummerland_coding.jpg 0 additions, 0 deletions...nt/blog/2024/06/2024-06-18_campdays/lummerland_coding.jpg
- content/blog/2024/06/2024-06-18_campdays/lummerland_gartentisch.jpg 0 additions, 0 deletions...og/2024/06/2024-06-18_campdays/lummerland_gartentisch.jpg
- content/blog/2024/06/2024-06-18_campdays/lummerland_loeten.jpg 0 additions, 0 deletions...nt/blog/2024/06/2024-06-18_campdays/lummerland_loeten.jpg
- content/blog/2024/06/2024-06-18_campdays/lummerland_test.jpg 0 additions, 0 deletionscontent/blog/2024/06/2024-06-18_campdays/lummerland_test.jpg
- content/blog/2024/06/2024-06-18_campdays/sommerfest_ehrungen.jpg 0 additions, 0 deletions.../blog/2024/06/2024-06-18_campdays/sommerfest_ehrungen.jpg
- content/blog/2024/06/2024-06-18_campdays/sommerfest_grillen.jpg 0 additions, 0 deletions...t/blog/2024/06/2024-06-18_campdays/sommerfest_grillen.jpg
- content/blog/2024/06/2024-06-18_campdays/sommerfest_laufen.jpg 0 additions, 0 deletions...nt/blog/2024/06/2024-06-18_campdays/sommerfest_laufen.jpg
- content/blog/2024/06/2024-06-18_campdays/spardose_1.jpg 0 additions, 0 deletionscontent/blog/2024/06/2024-06-18_campdays/spardose_1.jpg
- content/blog/2024/06/2024-06-18_campdays/spardose_2.jpg 0 additions, 0 deletionscontent/blog/2024/06/2024-06-18_campdays/spardose_2.jpg
- content/blog/2024/06/2024-06-18_campdays/ssg_1.jpg 0 additions, 0 deletionscontent/blog/2024/06/2024-06-18_campdays/ssg_1.jpg
- content/blog/2024/06/_index.md 5 additions, 0 deletionscontent/blog/2024/06/_index.md
- content/blog/2024/07/2024-07-08_stellenausschreibung/index.md 145 additions, 0 deletions...ent/blog/2024/07/2024-07-08_stellenausschreibung/index.md
- content/blog/2024/07/2024-07-08_stellenausschreibung/sharepic.png 0 additions, 0 deletions...blog/2024/07/2024-07-08_stellenausschreibung/sharepic.png
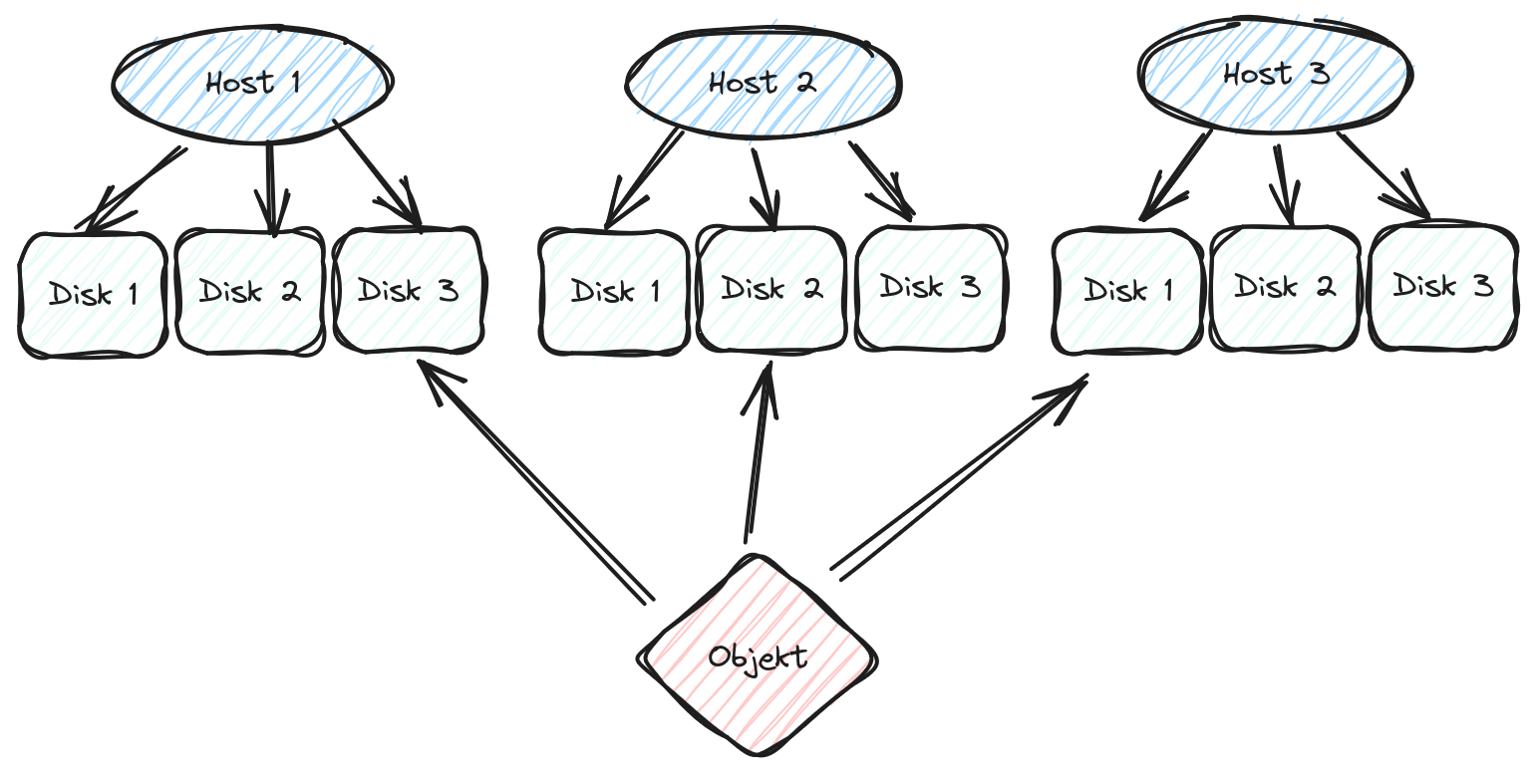
- content/blog/2024/07/2024-07-19_downtime-bericht/ceph-objekte.png 0 additions, 0 deletions...blog/2024/07/2024-07-19_downtime-bericht/ceph-objekte.png
- content/blog/2024/07/2024-07-19_downtime-bericht/index.md 355 additions, 0 deletionscontent/blog/2024/07/2024-07-19_downtime-bericht/index.md
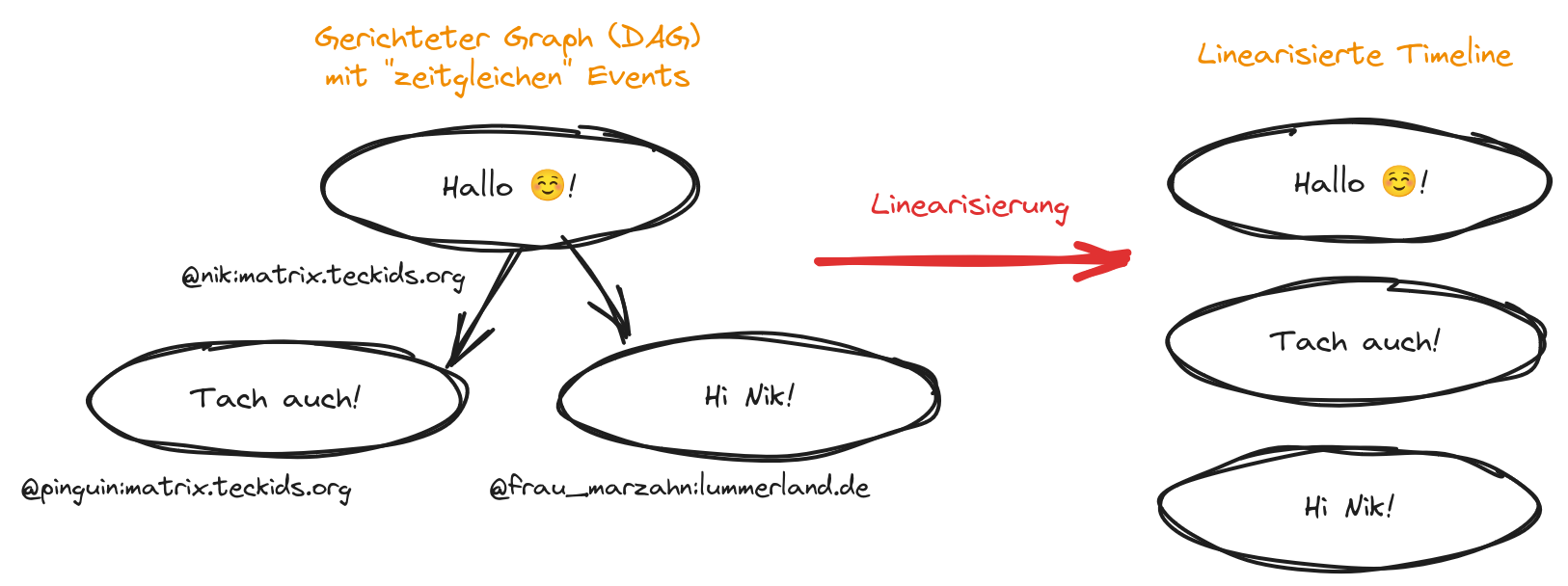
- content/blog/2024/07/2024-07-19_downtime-bericht/matrix-linearisierung.png 0 additions, 0 deletions.../07/2024-07-19_downtime-bericht/matrix-linearisierung.png
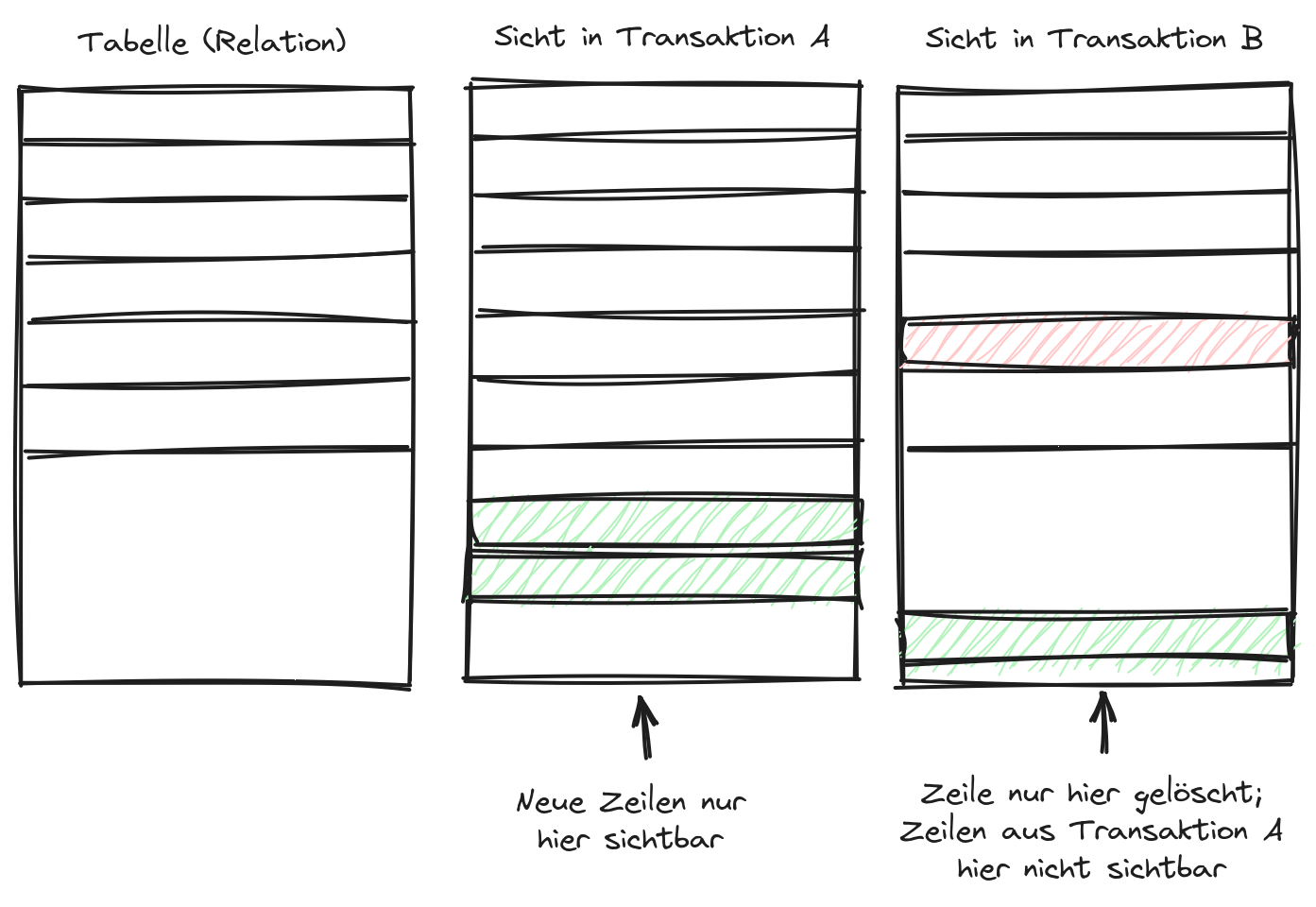
- content/blog/2024/07/2024-07-19_downtime-bericht/pg-transaktionen.png 0 additions, 0 deletions.../2024/07/2024-07-19_downtime-bericht/pg-transaktionen.png
- content/blog/2024/07/2024-07-19_downtime-bericht/rack-sharepic.jpg 0 additions, 0 deletions...log/2024/07/2024-07-19_downtime-bericht/rack-sharepic.jpg
{kind=link}

4.5 MiB
{kind=link}

3.54 MiB
{kind=link}

4.27 MiB
{kind=link}

4.09 MiB
{kind=link}

4.01 MiB
{kind=link}

4.35 MiB
{kind=link}

1.39 MiB
{kind=link}

4.88 MiB
{kind=link}

2.8 MiB
{kind=link}

2.07 MiB
{kind=link}

2.16 MiB
content/blog/2024/06/_index.md
0 → 100644
{kind=link}

89.9 KiB
{kind=link}
413 KiB
{kind=link}
165 KiB
{kind=link}
299 KiB
{kind=link}

420 KiB